
We've updated this course, so the videos don't exactly match the lessons. However, we've included them for you to review, and we will update them later in 2025.
We've updated this course, so the videos don't exactly match the lessons. However, we've included them for you to review, and we will update them later in 2025.
After completing this lesson, you’ll be able to:
FME readers and writers can work with compressed, archived files of various formats. As well as a size reduction, these file types are a convenient way to store datasets that need handling as a single unit, for example, a set of multiple dataset files contained within a single zip file.
FME can read the following archive formats:
The dataset a reader reads is defined by the Source Dataset/Files parameter in the Navigator window:
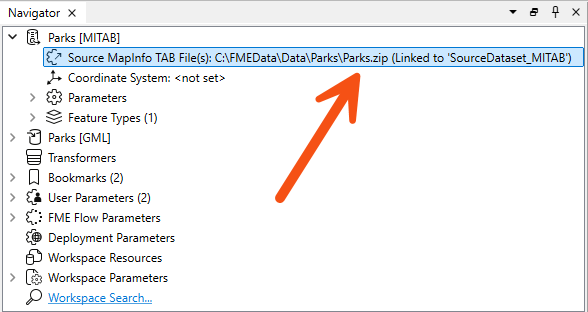
This dataset parameter can point to an archived file, as illustrated in the above screenshot. You select the archive file in the source parameter, and FME will extract the data when it reads it.
This technique works whether the archived dataset is file-based (like a single AutoCAD file) or folder-based (like the set of files that make up a Shapefile dataset).
Because FME supports reading archived files, you might notice the default file filter includes archive formats when browsing for a reader dataset:
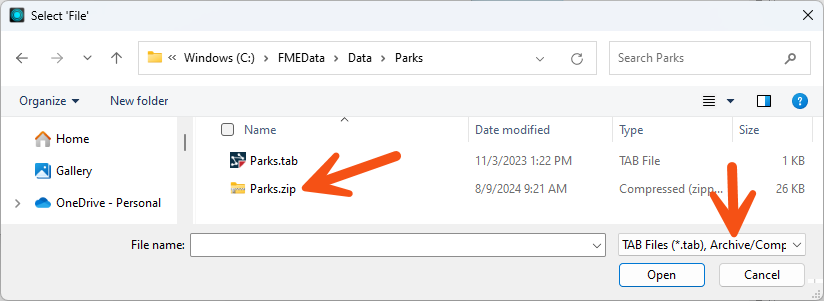
You can include wildcards when reading archive files just like when you read normal files. See the documentation for examples.
Writing data as a zip file is particularly useful when the output data needs to be post-processed. For example, if you use a shutdown script to move or copy output data to a new location, handling a single archive file is more convenient than multiple data files.
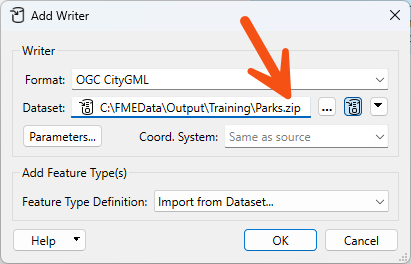
The simplest way to create a zipped output is to change the file extension in the output dataset field:
You can also specify the filename to be written inside the archive file. A shortcut button does this for you:
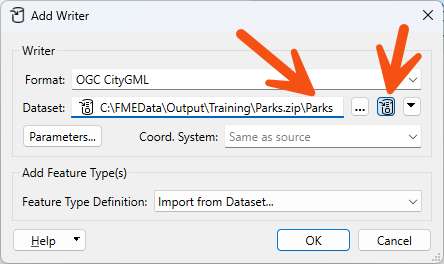
Notice the small icon in the left of the dataset field that indicates the zipped status.
Some users may want to archive data as a single entity to move or copy it to a different location. A user parameter can be used in a TCL or Python shutdown script to find the file's name just written, and the FeatureWriter transformer also provides the name of the dataset as an attribute.
When the workspace is run, the log file reports the file creation at various points:
MULTI_WRITER: Output will be zippedZipping contents of temporary datasetFinished updating output zip file: `C:\FMEData\Output\Parks.zip'
...and the output is, indeed, a zip file:
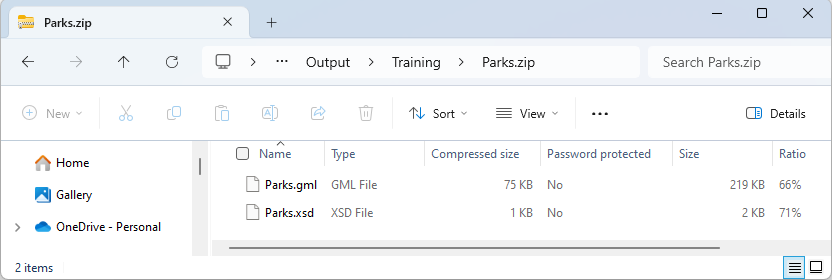
Some users may want to archive data as a single entity to move or copy it to a different location. A user parameter can be used in a TCL or Python shutdown script to find the written file's name, and the FeatureWriter transformer also provides the name of the dataset as an attribute.